And Now for Something Very..Similar..
In my basic web scraping in R series, I covered how to build a data set for all movies in the IMDb List of Top Rated Sci-Fi Movies using the rvest web scraping library for R. At the end of the final post of that series, I indicated that I would write a short tutorial on how to use some of the fundamental skills covered therein to scrape existing HTML tables from the web. That’s going to be the focus of this post.
 And now for something very..similar..
And now for something very..similar..
While the workflow detailed here is simple and relatively self-contained, a basic knowledge of rvest functions and how to identify data-containing HTML elements using CSS selectors will certainly make it easier to follow; I won’t be explaining those concepts again here. So, if you haven’t already, I would recommend at least reading through the three posts in my basic web scraping in R series. If you’re already a HTML guru, great! Let’s scrape ourselves some data.
Web Scraping Tables - Easy
The first table we will scrape in this post is the RateBeer.com Top 50 beers. The table contains 5 variables (columns) recorded for each of the 50 observations (rows) i.e. beers in the data set, these are: the ordered ranking, beer name, rating score, count (number of ratings) and style of beer. The actual content of this data set is essentially irrelevant; I picked it because (a) I like beer and (b) it is a good example of an easy to scrape web table. It also contains a nice, simple data set, so the code is quick and easy to run.
Let’s first load the packages we will require for this exercise. If you do not have the dplyr and rvest packages installed you can do this by simply removing the “#” and running the install.packages() function calls.
## install packages
# install.packages("dplyr")
# install.packages("rvest")
## load packages
library("dplyr")
library("rvest")
Now, navigate to the link above, copy the URL from your address bar and assign it to a variable in your R session.
# assign URL to variable
url <- "https://www.ratebeer.com/beer/top-50/"
Next, we will use the read_html() function which returns the source code for a HTML document from a specified URL. Here we will supply the url variable we just created and assign the output to a new page variable.
# read HTML document source code
page <- read_html(url)
At this point, we could use the SelectorGadget browser extension to generate the CSS selectors required to identify and extract each table column as seperate variables and reconstruct the table from those, in much the same way that did in the first post of the basic web scraping series. Sometimes this can be the only way; a website might be formatted such that information appears to be contained within a table but in reality, the <table> HTML tag is nowhere to be seen. The lists on IMDb are a good example of this.
When information on a website is contained within a HTML table element, we can scrape the entire data set and import it into R as a data frame using the convenient html_table() function from rvest.
The first thing we need to do this is the name of the table, which we can get using the inspect functionality of Google Chrome; right-click the table and click “Inspect” to specifically inspect this element:
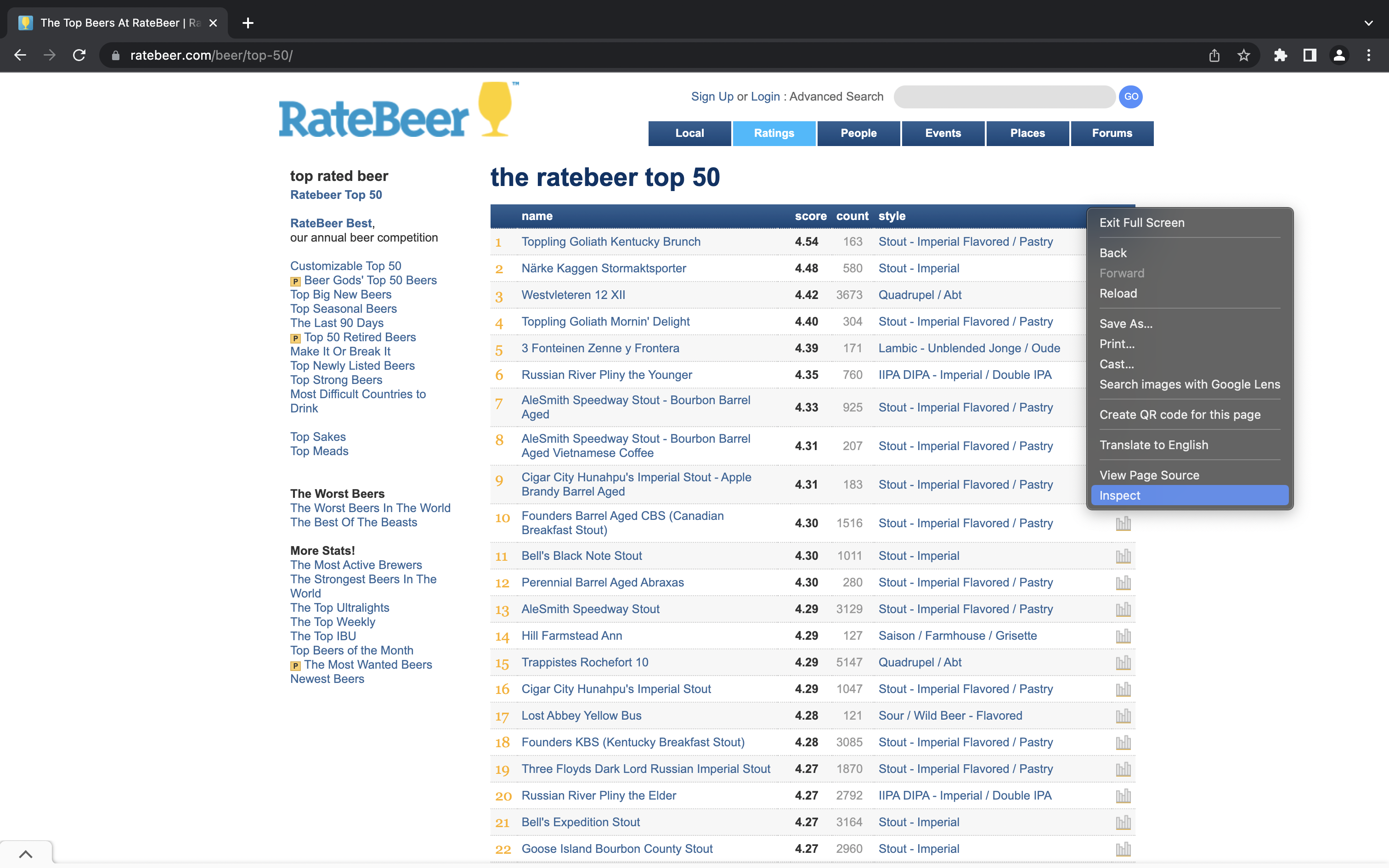 Click to Zoom
Click to Zoom
When the inspector window opens, find and hover over the HTML <table> tag (highlighted in blue at the top of the panel on the right-hand side) and the name of the respective element will be shown in the active browser window, as shown below:
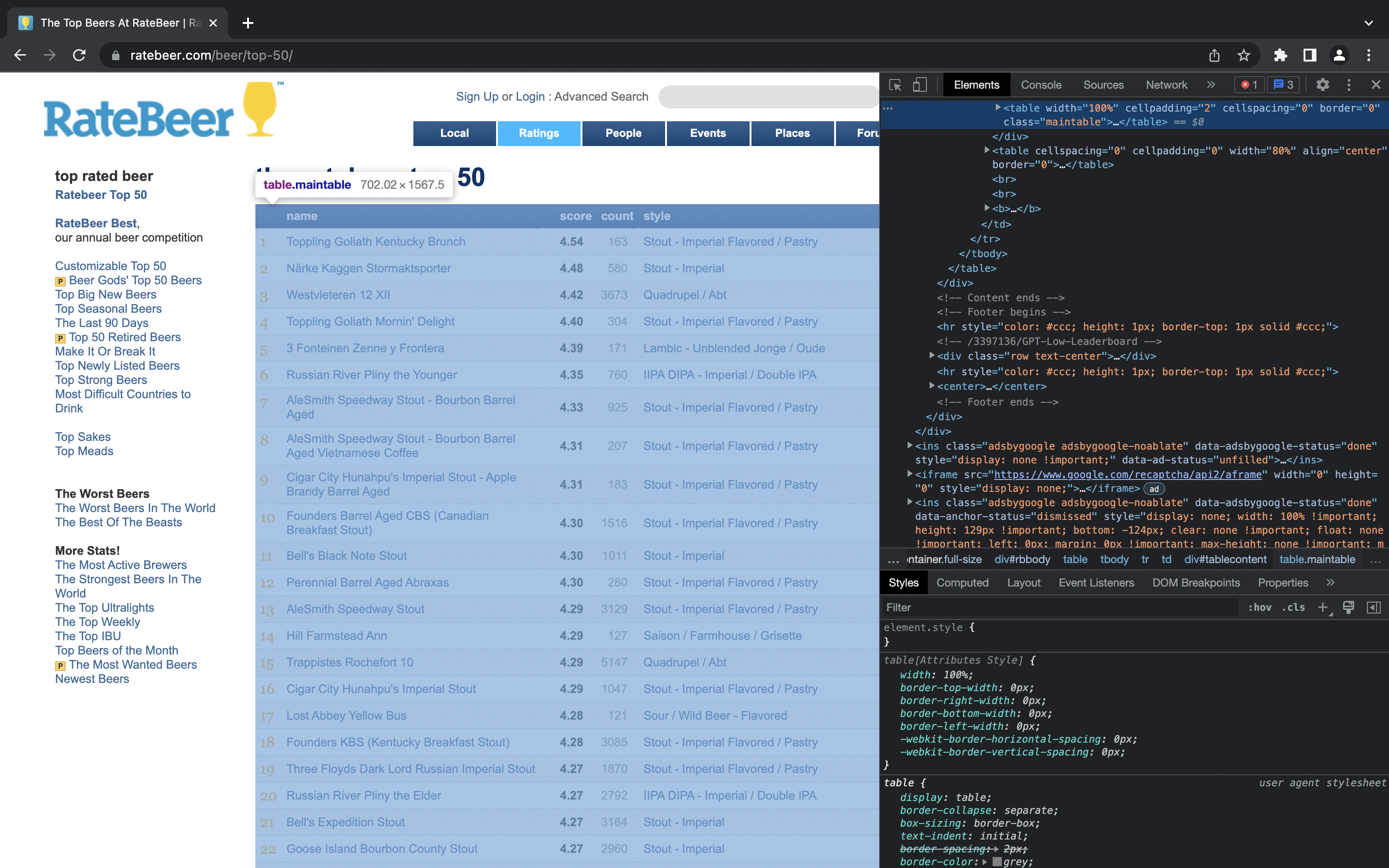 Click to Zoom
Click to Zoom
As you can see, the table name in this case is “table.maintable”. We can now use this, along with the page variable we created in the last step, as input to the html_element() function. The resultant output is passed to the html_table() function, which will parse the exact table element we specified into an R data frame.
# scrape table
raw_table <- page %>%
html_element("table.maintable") %>%
html_table()
That’s job done in terms of scraping this table. Running View(raw_table) will allow you to have a look at the resultant data frame; the output should resemble the one shown below.
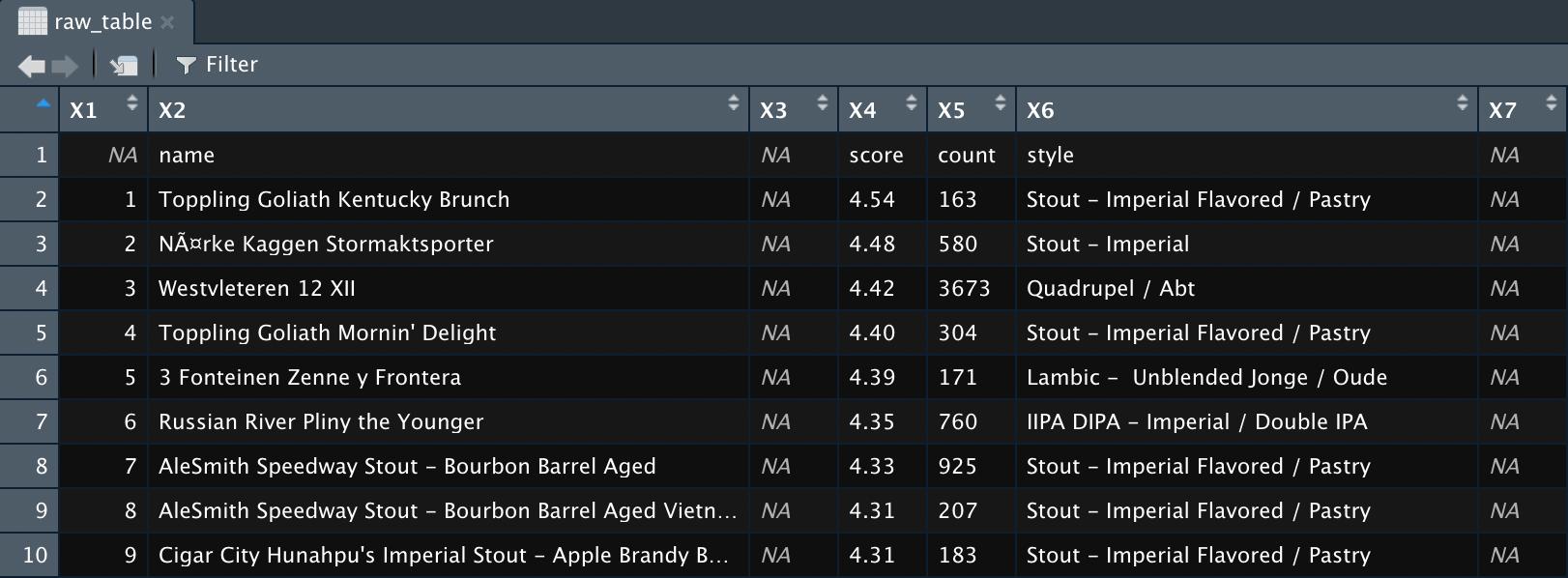 Click to Zoom
Click to Zoom
As you can probably see in the screenshot or your own RStudio session, the newly scraped table needs a tiny bit of extra work to be ready to use; the variable names (which have a value missing) wrongly comprise the first row of the data, there are empty columns that need removing, and the data is in the wide (cartesian) format. A detailed walkthrough of data cleaning and transformation is outside of the scope of this post, but I have included some bonus code below that will take it to an analysis-ready tidy format incase you want to experiment with it. Have fun 😉
Click to Show / Hide Bonus Code
## install packages
# install.packages("magrittr")
# install.packages("stringr")
# install.packages("tidyr")
## load packages
library("magrittr")
library("stringr")
library("tidyr")
# create vector of column names
column_names <- raw_table %>%
# remove empty columns
select(-c(3, 7)) %>%
# extract first row containing column names as they appear on web
slice_head() %>%
# convert to character vector from data frame
as.character() %>%
# replace missing column name
str_replace("NA", "rank")
# clean scraped raw data table
beer_table <- raw_table %>%
# remove empty columns
select(-c(3, 7)) %>%
# remove first row
slice(-1) %>%
# set column names using vector created above
set_colnames(column_names)
# view table
View(beer_table)
# transform data frame to long (tidy) format
beer_table_tidy <- beer_table %>%
pivot_longer(
cols = score:style,
names_to = "variable",
values_to = "value"
)
# view table
View(beer_table_tidy)
Web Scraping Tables - More Tricky
Occasionally, you will find a website that contains a HTML table for which the scraping approach we have just used won’t work. Wikipedia is a good example of a website where this situation will occur. Let’s use Wikipedia to demonstrate both the problem and the solution.
Sticking with the beer theme, if we visit the Wikipedia List of Beer Styles page we can see three tables: one detailing classic styles of beer, another detailing hybrid and speciality styles, and a third detailing county of origin.
Using the first table as an example; if we repeat the process of right-clicking, selecting “Inspect”, and then hovering over the table HTML tag in the inspector window, we can see the table is identified by “table.wikitable.sortable.jquery-tablesorter”.
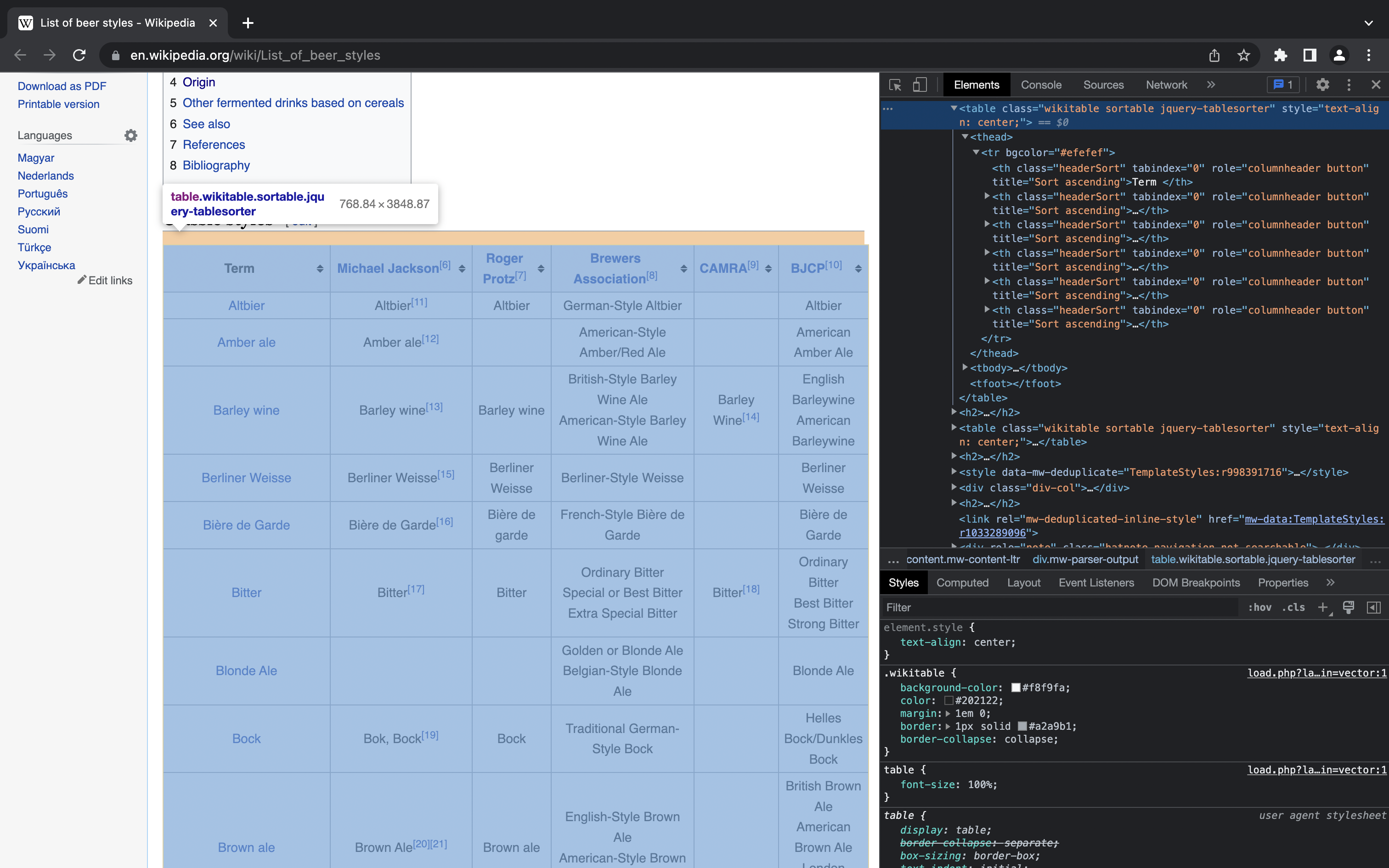 Click to Zoom
Click to Zoom
Inserting the web page URL and the CSS selector we have just identified into the code we used in the easy table web scraping example above gives the following:
# assign URL to variable
url <- "https://en.wikipedia.org/wiki/List_of_beer_styles"
# read HTML document source code
page <- read_html(url)
# attempt to scrape table
raw_table <- page %>%
html_element("table.wikitable.sortable.jquery-tablesorter") %>%
html_table()
Running this will result in an error:
Error in UseMethod("html_table") :
no applicable method for 'html_table' applied to an object of class "xml_missing"
Without getting into the details too much, the reason for this issue is essentially that “table.wikitable.sortable.jquery-tablesorter” is a null node set. This is a common problem you will likely encounter fairly frequently when trying to web scrape tables. There’s no need to fall back to the more typical variable-by-variable scraping approach though, we just need to make a couple of minor modifications to our code in order to scrape the table as-is.
First, we need to inspect the table nodeset on the page. We can do this by changing the html_element() function to html_elements() and modifying the CSS selector passed to the html_elements() function from “table.wikitable.sortable.jquery-tablesorter” to “table”.
# extract table nodeset
table_nodeset <- page %>%
html_elements("table")
# print result to console
print(table_nodeset)
Running this shows the nodeset for all HTML table tags on the page:
{xml_nodeset (6)}
[1] <table class="wikitable sortable" style="text-align: center;"><tbody>\n<tr bgcolor="#efefef">\n<t ...
[2] <table class="wikitable sortable" style="text-align: center;"><tbody>\n<tr bgcolor="#efefef">\n<t ...
[3] <table class="wikitable sortable" style="text-align: center;"><tbody>\n<tr bgcolor="#efefef">\n<t ...
[4] <table class="nowraplinks hlist mw-collapsible autocollapse navbox-inner" style="border-spacing:0 ...
[5] <table class="nowraplinks hlist mw-collapsible autocollapse navbox-inner" style="border-spacing:0 ...
[6] <table class="nowraplinks navbox-subgroup" style="border-spacing:0"><tbody>\n<tr>\n<th id="Sour_b ...
As you can see from the console output, there are six HTML <table> tags on the page; the top three are of the type we encountered when inspecting the page (wikitable sortable) so it’s a fair guess that the top three are the three beer-related tables on the page.
Using the entire nodeset in the pipeline of html_elements() and html_table() functions will result in a list object containing one data frame element per table on the web page.
# scrape list containing one data frame for each table on page
tables_list <- page %>%
html_elements("table") %>%
html_table()
# view list of scraped tables
View(tables_list)
All we need to do to get the table of interest, in this case the first table of classic styles of beer, is to add a command to extract the respective list element. There are a couple of ways of doing this; I prefer the extract2() function from the magrittr package, passing to it the index of the list element to extract.
# scrape table
beer_styles <- page %>%
html_elements("table") %>%
html_table() %>%
extract2(1)
# view table
View(beer_styles)
Mischief managed. I haven’t included any extra code for cleaning or transformation of this data frame as I only wanted to demonstrate the null nodeset issue posed by tables using JavaScript libraries like jQuery, and how to solve it.
Summary
In this post, we have covered the functions and approaches required to web scrape HTML tables and parse them into an R data frame. Along with the information covered in my basic web scraping in R series, we have now covered all the information required to successfully carry out a multitude of basic and intermediate level web scraping tasks in R.
As I mentioned in the last basic web scraping in R post, I will probably revisit the topic of web scraping in future to cover more intermediate- and advanced-level scenarios, as well as how to scrape web data using Python. For now, that’s more than enough web scraping. Time for a beer!
Thanks for reading. I hope you enjoyed the article and that it helps you to get a job done more quickly or inspires you to further your data science journey. Please do let me know if there’s anything you want me to cover in future posts.
Happy Data Analysis!
Disclaimer: All views expressed on this site are exclusively my own and do not represent the opinions of any entity whatsoever with which I have been, am now or will be affiliated.