Web Scraping
Web scraping or web data extraction is the process of extracting data from websites. In this series of tutorials we are going to use the rvest package to scrape some basic unstructured data from a series of web pages (IMDb Top Rated Sci-Fi Movies) and parse it into an R data frame. We can use the resultant data set in future posts to learn how to clean, summarise, describe, transform, model and visualise data during an exploratory analysis.
 By the end of this series you will have a very particular set of skills…
By the end of this series you will have a very particular set of skills…
HTML and CSS
HTML (hypertext markup language) is the code used to structure a web page and its content. CSS (cascading style sheets) is the language used to style HTML documents; it describes how HTML elements should be displayed. Let’s quickly cover the basics of these in order to understand how to refer to specific HTML elements using CSS. This will allow us to extract data from HTML into structured objects.
HTML has a hierarchical structure formed by elements that consist of paired start and end tags (e.g. <tag></tag>), optional attributes, and contents i.e. everything between the start and end tags. Over 100 types of HTML elements exist. A simple example of a HTML document might look like this:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Webpage Title</title>
</head>
<body>
<div>
<h1 id="Heading_1">First Heading on Page</h1>
<p>A whole load of text<b>some bold text</b>a whole load more text</p>
<img src="whitty_cartoon.png" width="400" height="300">
</div>
</body>
</html>
Every HTML page exist within a pair of <html> element tags. These must contain within them a set of paired <head> and <body> element tags which contain document metadata (e.g. page title) and the content you see in the browser, respectively. Block tags like <h1> (heading level 1) and <p> (paragraph) form the overall structure of the page, while inline tags like <b> (bold), <i> (italics), and <a> (links) format the text within the block tags.
Most elements can have content between their start and end tags. This content can either be text or more nested elements. Nested elements are referred to as child elements or children, while text contents are not. In the example above the <p> element has both text content and one child - the <b> element. The <b> element itself has no children but does still have content i.e. the text “some bold text”.
Some elements, like <img> can’t have children. These elements depend solely on attributes for their behaviour. In the example above, “src” is an attribute. Two of the most important attributes are “id” and “class”, which are used in conjunction with CSS to control the visual appearance of the page.
CSS includes within it a miniature language for selecting elements on a page called CSS selectors. CSS selectors define patterns for locating HTML elements and are useful for the process of web scraping because they provide a concise way of describing elements that you might want to extract.
The TL;DR
In order to scrape data from a web page you’ll need some way to identify the elements that contain the data you want. The rvest package provides two options for this: CSS selectors and XPath expressions. We are going to use CSS selectors because they’re relatively simple but still sufficiently powerful for most scraping tasks.
Selector Gadget
Probably the most easy way to identify the CSS selectors we need to begin scraping data is to use the SelectorGadget browser extension. This handy tool will automatically generate the CSS selector you need by supplying positive and negative examples inside an active browser window. More on this shortly.
Scraping a Single Web Page
Let’s first load the packages we will require for this exercise. If you do not have the dplyr and rvest packages installed you can do this by simply removing the “#” and running the install.packages() functions as shown.
## install packages
# install.packages("dplyr")
# install.packages("rvest")
## load packages
library("dplyr")
library("rvest")
In this series of posts we will be scraping data from the IMDb Top Rated Sci-Fi Movies. The data set that we are going to extract will eventually consist of 7 different variables recorded for all movies in this list. We will begin to work-up the code required by scraping some data from a single top-level page for the first 50 movies.
First, navigate to the IMDb link above, copy the URL from your address bar and assign it to a variable in your R session.
# assign the URL to a variable
url <- "https://www.imdb.com/search/title/?genres=sci_fi&sort=user_rating,desc&title_type=feature&num_votes=25000,&pf_rd_m=A2FGELUUNOQJNL&pf_rd_p=5aab685f-35eb-40f3-95f7-c53f09d542c3&pf_rd_r=9XADGPNFYQM0JP3Q5N2R&pf_rd_s=right-6&pf_rd_t=15506&pf_rd_i=top&ref_=chttp_gnr_17"
Next, go back to your browser window and open the SelectorGadget browser extension:
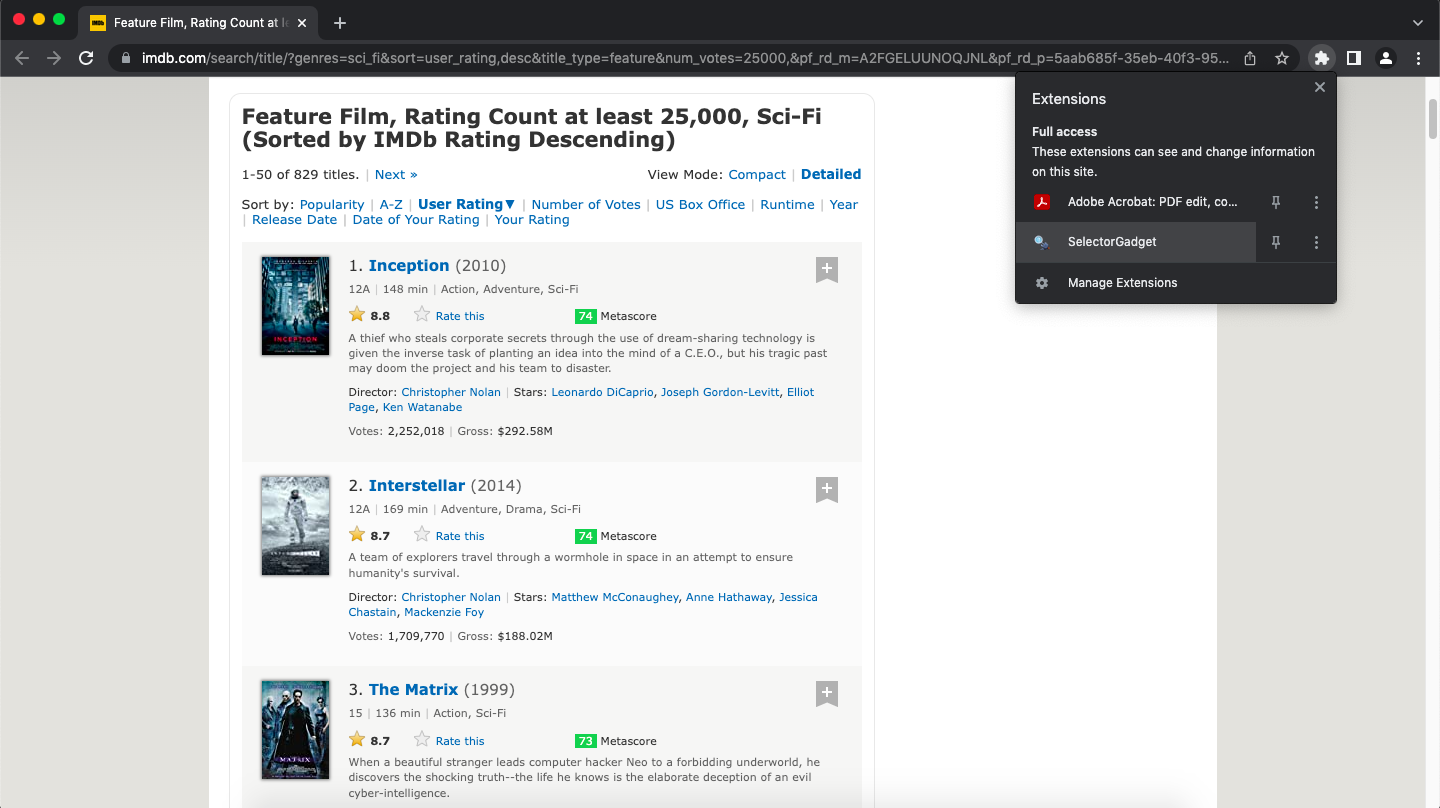 Click to Zoom
Click to Zoom
Select one of the movie titles. This will result in elements of a similar type being highlighted, as shown:
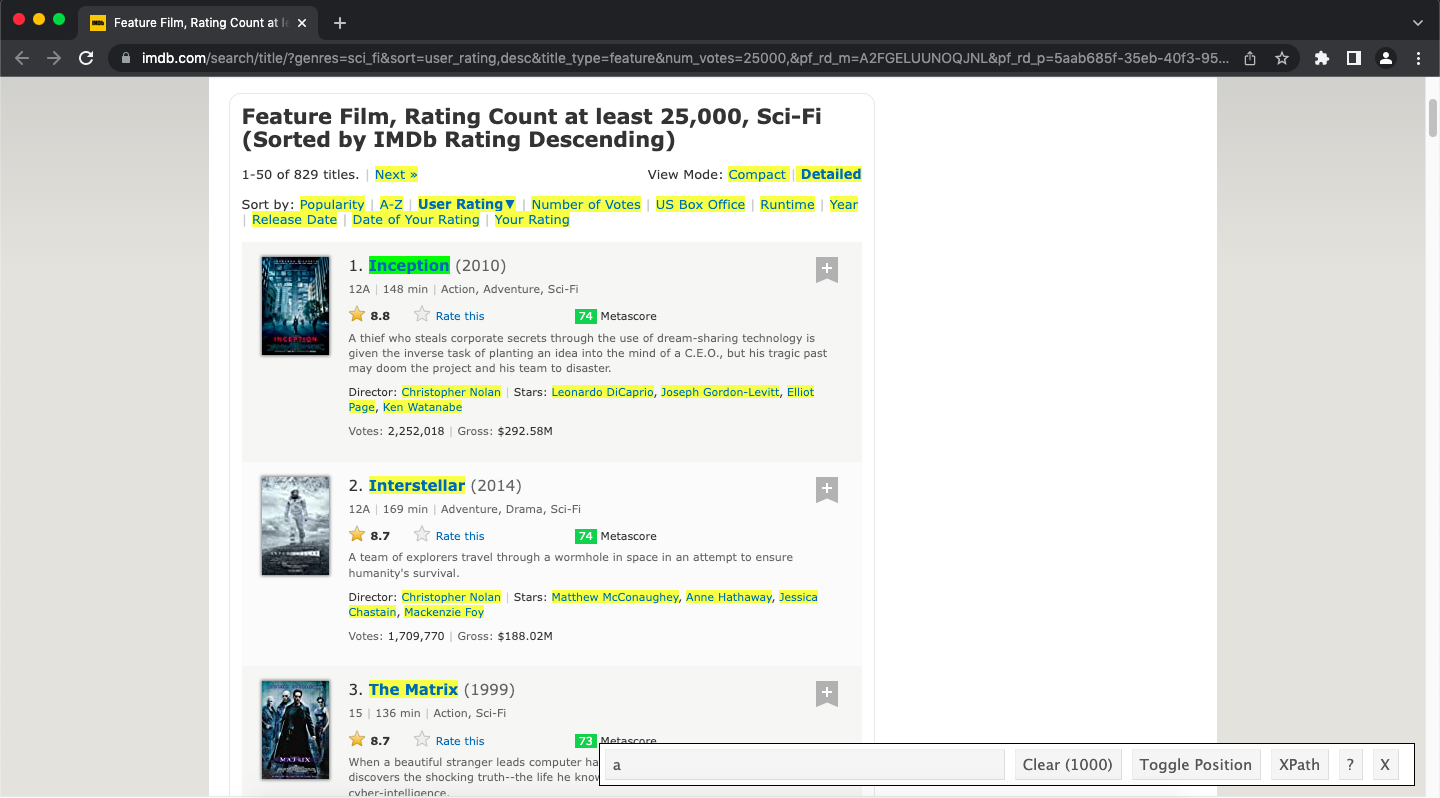 Click to Zoom
Click to Zoom
Deselect elements by clicking on them in sequence until only the element of interest is highlighted. For example, clicking the link for the director of a movie (e.g. Christopher Nolan) results in only the element containing the movie title being highlighted:
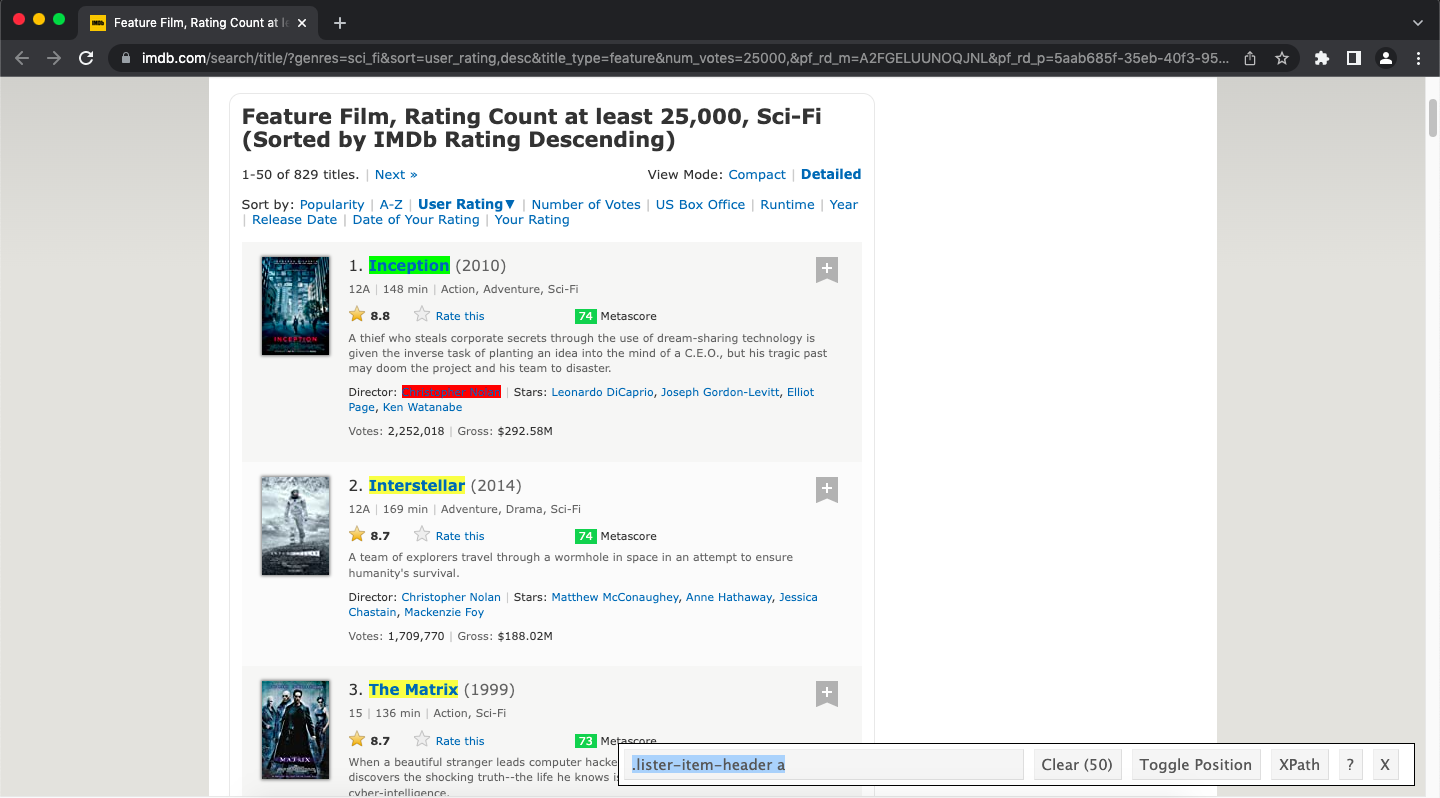 Click to Zoom
Click to Zoom
We can do a quick sanity check to ensure that the correct CSS selector has been identified by looking at the SelectorGadget dashboard on the bottom right of the browser window: the “Clear” button now shows how many elements are selected (50) which is the expected number (one title per movie) for this page. Copy the CSS selector (in this case “.lister-item-header a”) from the SelectorGadget dashboard to the clipboard and go back to your R session.
Next, we will use the read_html() function which returns the source code for a HTML document from a specified URL. Here we will supply the “url” variable we created earlier and assign the output to a new variable.
# read the HTML document source code
page <- read_html(url)
We can now use the newly created “page” variable as input to a series of two functions. The html_elements() function extracts the HTML elements specified by the CSS selector, in this case the “.lister-item-header a” selector that we just grabbed. The html_text() function then extracts the actual text content from these elements.
# extract movie titles
title <- page %>%
html_elements(".lister-item-header a") %>%
html_text()
Now you can go back to your browser window, clear the current CSS selector by clicking the “Clear” button in the SelectorGadget dashboard, and repeat the entire process three more times for the year, runtime and IMDb rating. Your code should eventually look something like this:
# extract movie release year
year <- page %>%
html_elements(".text-muted.unbold") %>%
html_text()
# extract movie runtime
runtime <- page %>%
html_elements(".runtime") %>%
html_text()
# extract IMDb rating
imdb_rating <- page %>%
html_elements(".ratings-imdb-rating strong") %>%
html_text()
The more observant amongst you may have noticed that some movies have multiple directors (e.g. The Matrix) or have missing gross profit data (e.g. Spider-Man: No Way Home). Issues like this could be problematic. Thankfully I have devised a couple of relatively simple workarounds to ensure we capture all of the director data entries and that the gross profit variable is of the correct length to enable construction of a data frame. These solutions will be fully realised when we clean the data in a future tutorial series. For now we just have to make sure that we extract the entire paragraph element (defined by paired <p> block tags) containing the required information (along with some extra junk we’ll dispose of in future). If you correctly identify the CSS selectors required then you should end up with this:
# extract movie director
director <- page %>%
html_elements(".text-muted+ p") %>%
html_text()
# extract the gross profit
gross_boxoffice <- page %>%
html_elements(".sort-num_votes-visible") %>%
html_text()
Now all that’s left to do for the time being is to construct a data frame from the data we have scraped so far and marvel at how easy that was:
# combine variables into a data frame
imdb_data <- data.frame(title, year, director, runtime, gross_boxoffice, imdb_rating)
# have a brief self-congratulatory moment
View(imdb_data)
In the next two posts in this series I will cover how to automatically scrape data from multiple pages; both sequential top-level and nested pages.
Thanks for reading. I hope you enjoyed the article and that it helps you to get a job done more quickly or inspires you to further your data science journey. Please do let me know if there’s anything you want me to cover in future posts.
Happy Data Analysis!
Disclaimer: All views expressed on this site are exclusively my own and do not represent the opinions of any entity whatsoever with which I have been, am now or will be affiliated.