Even More Web Scraping
In the first post in this series, we covered the fundamentals of HTML and CSS, how to identify data-containing HTML elements using CSS selectors, and a basic workflow for scraping text data from a single web page. In the previous post, we covered the basics of scraping data from a sequential series of pages using a for-loop for controlling flow and specifying iteration. In this post, we are going to develop some basic code for scraping data from nested web pages; the final step required to fulfil our goal of building a data set for all movies in the IMDb List of Top Rated Sci-Fi Movies.

Note: I am going assume that anyone reading on from this point will have been through the previous two posts in the series, installed and loaded the dplyr and rvest packages into R, and have all of the code chunks from the previous posts stored in a script. If not, go follow the first two posts, swipe all the code, and let’s scrape ourselves some more data.
Nested Web Pages
A nested page is one of the many sub-pages that are linked from a top-level page. For example, if we were to visit this page, the one we have been working with so far, and then click on the “Inception” movie title hyperlink, it would take us to the sub-page shown below.
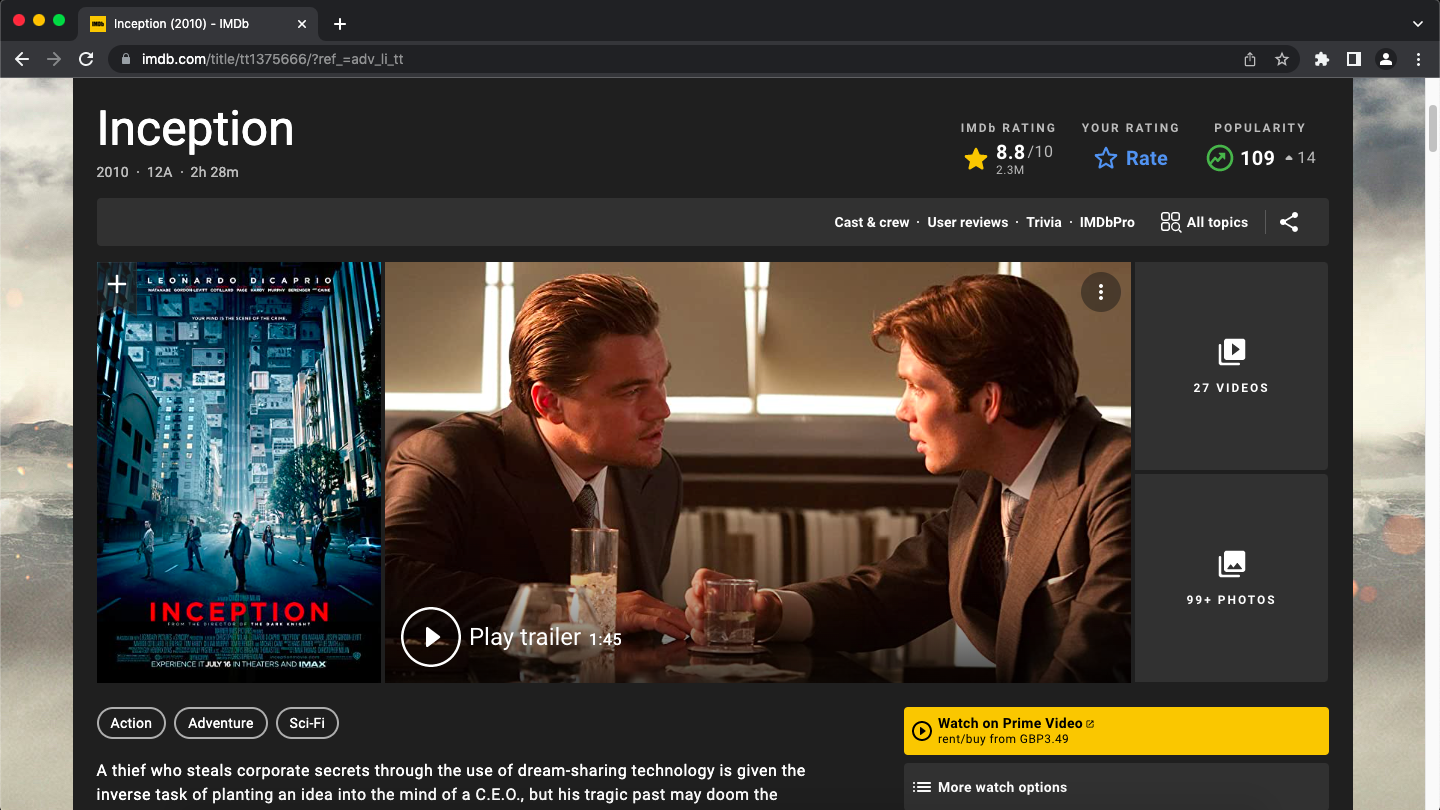 Click to Zoom
Click to Zoom
To demonstrate nested page scraping, we are going to use the Metacritic review score or metascore. Some movies have missing metascore data on the top-level pages we have been scraping data from thus far. If we harvest metascore data from nested pages we will at least get a vector of 50 data elements per top-level page (one per movie / nested URL), even though some will be “NA” or missing data. Scraping variables which are all the same length using a resourceful approach such as this can make constructing a final data frame much easier, and dealing with missing data later is fairly easy.
Fun with URLs
The first thing we will need to do is find a way of collecting all 50 URLs that link to the respective “Critic Reviews” page for every title listed on each of the 17 top-level pages we visit in our for-loop. The trick to this lies in realising that, for any given page type e.g. “Critic Reviews”, the only thing that changes in the URL between different movies is the IMDb movie identifier. Consider the following two URLs:
# spot the difference
https://www.imdb.com/title/tt1375666/criticreviews?ref_=tt_ql_6
https://www.imdb.com/title/tt0409459/criticreviews?ref_=tt_ql_6
At the time of writing, these are the links to the “Critic Reviews” page for “Inception” and “Watchmen”, which are movie #1 and #101 on the list; the only thing that changes here is the IMDb movie identifier “tt[numbers]” that appears after “imdb.com/title/”. This means all we need to do is figure out a way of getting the identifier for each movie on a top-level page, dynamically alter these components inside our script, visit all the URLs, perform scraping tasks, store the data, move to the next top-level page, rinse and repeat. As you might have guessed from last time, we are going to automate this process.
When we identified the CSS selector and corresponding HTML element to scrape movie titles back in the first post in this series, we actually already had all of the information required to grab the IMDb identifier for each movie but just need to use a slightly different approach to be able to access it. Let’s take a look at the basic code for this purpose; we will eventually insert this into the for-loop we built last time:
# parse urls for nested pages into a vector of character strings
nested_page_urls <- page %>%
html_elements(".lister-item-header a") %>%
html_attr("href") %>%
sub(pattern = "\\?ref_=adv_li_tt", replacement = "", x = .) %>%
paste0("https://www.imdb.com", ., "criticreviews?ref_=tt_ql_6")
The page variable (containing the top-level page HTML document) is passed to the the html_elements() function and all HTML elements specified by the “.lister-item-header a” CSS selector are extracted.
The HTML element identified for each movie by “.lister-item-header a” is the HTML <a> tag that defines the title hyperlink for each movie in this case. As well as the text content (i.e. the respective movie title) that we have previously extracted, each <a> tag also contains a “href” attribute that specifies the actual URL for the hyperlink that our browser follows when we click it. For example, the <a> tag for “Inception” looks like this:
<a href="/title/tt1375666/?ref_=adv_li_tt">Inception</a>
Using the html_attr() function with “href” as input to the first argument extracts all of the “href” attribute information from all HTML <a> tags identified by the “.lister-item-header a” on the current top-level page. So, in the “Inception” example, the data extracted would be “/title/tt1375666/?ref_=adv_li_tt”.
As you can see in this example, the IMDb identifier “tt1375666” is sandwiched between “/title/” and “?ref_=adv_li_tt” character strings. The call to the sub() function removes the latter string by substituting it for nothing. The “/title/” string is left in place as it is actually used in the URL for nested pages; pointless to remove it and then add it back in the next step.
The output of the sub() function call is then passed to the paste0() function, which simply concatenates the IMDb identifier with the required static character strings to create the nested page URLs. Each of the URLs created links to the respective “Critic Reviews” page for all movies on the top-level page being read on any given for-loop iteration. These URLs are finally assigned to the nested_page_urls variable.
Scraping Data from Nested Web Pages
To actually scrape the data, we could use a small for-loop within the one we have already created that would iterate over all 50 values of the nested_page_urls and scrape the required data. However, nested for-loops like this can soon become messy and hard to keep track of, although they are a perfectly viable option. A more elegant and efficient solution would be to create a user-defined function outside of the loop and then apply this to all 50 values of the nested_page_urls variable. This would return a vector of 50 metascores during each for-loop iteration. Such a function might look like this:
# user-defined function for scraping data from nested pages
scrape_nested_pages <- function(nested_page_url) {
read_html(nested_page_url) %>%
html_elements(".score_favorable span") %>%
html_text()
}
This function works in exactly the same way as the code chunks we wrote in the first post, the only difference being that we pass in a nested page URL instead of using the page variable; the HTML document read by the function is one of the “Critic Reviews” pages rather than the top-level page that the rest of the for-loop body is scraping data from.
The CSS selector “.score_favorable span” used by the function was identified by navigating to one of the “Critic Reviews” pages and using the SelectorGadget to identify the HTML element housing the metascore data:
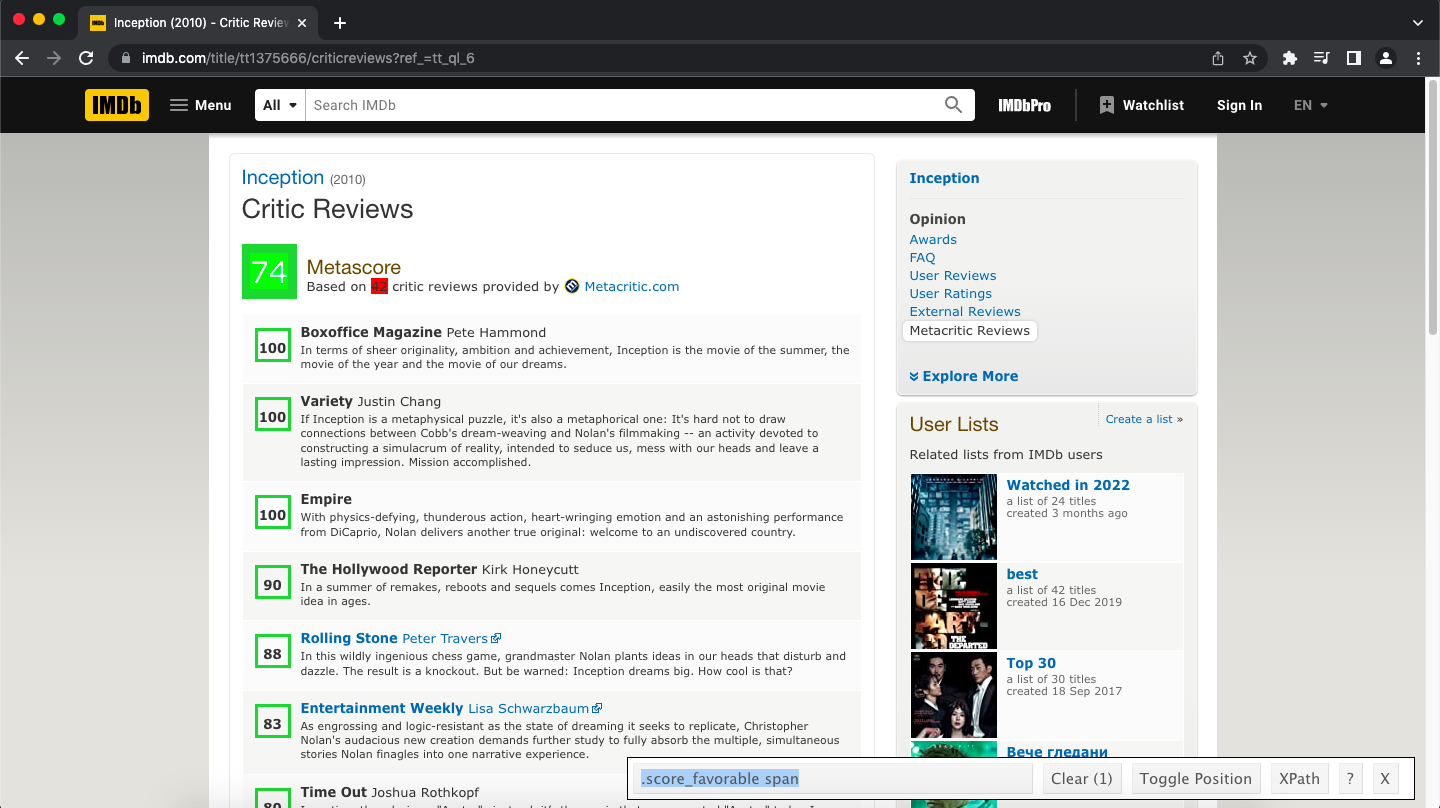 Click to Zoom
Click to Zoom
Now that we have defined a function, let’s take a look at the code required to call this function within the for-loop, scrape the data from the nested pages and assign this data to a variable.
# scrape metascore from each nested page url
metascores <- sapply(nested_page_urls, FUN = scrape_nested_pages) %>% as.numeric()
The call to the sapply() applies the scrape_nested_pages() function that we have just defined to each of the 50 URLs stored within the nested_page_urls variable during any one loop iteration and simplifies the result to a vector. Passing the output of sapply() to as.numeric() before output is assigned to metascores means that the scraped character data is coerced to integer data, which automatically converts empty strings to “NA”; this will save a tiny bit of hassle when we clean the data set in another tutorial.
The Final Iteration
If we now reinstate all of the code we had written at the end of the previous post in this series and add in the appropriate code chunks from this post to your for-loop, the script that you have written so far should look something like this:
# user-defined function for scraping data from nested pages
scrape_nested_pages <- function(nested_page_url) {
read_html(nested_page_url) %>%
html_elements(".score_favorable span") %>%
html_text()
}
# create a sequence of top-level page numbers to use in the loop
top_level_numbers <- seq(from = 1, to = 801, by = 50)
# create storage object of length equal to output object - preallocation of memory
store_data <- vector(mode = "list", length = length(top_level_numbers))
# name the list entries by number enabling these to be called and data assigned on each loop iteration
names(store_data) <- top_level_numbers
# for-loop
for (number in top_level_numbers) {
# console output for progress monitoring
cat("Working on entries beginning with entry", number, "\n")
# alter the URL by substituting the page number
url <- paste0("https://www.imdb.com/search/title/?title_type=feature&num_votes=25000,&genres=sci-fi&sort=user_rating,desc&start=",
number,
"&ref_=adv_prv")
# read the HTML code for the page at the specified URL
page <- read_html(url)
# extract movie titles
title <- page %>%
html_elements(".lister-item-header a") %>%
html_text()
# extract movie release year
year <- page %>%
html_elements(".text-muted.unbold") %>%
html_text()
# extract movie director
director <- page %>%
html_elements(".text-muted+ p") %>%
html_text()
# extract movie runtime
runtime <- page %>%
html_elements(".runtime") %>%
html_text()
# extract the gross profit
gross_boxoffice <- page %>%
html_elements(".sort-num_votes-visible") %>%
html_text()
# extract IMDb rating
imdb_rating <- page %>%
html_elements(".ratings-imdb-rating strong") %>%
html_text()
# parse urls for nested pages into a vector of character strings
nested_page_urls <- page %>%
html_elements(".lister-item-header a") %>%
html_attr("href") %>%
sub(pattern = "\\?ref_=adv_li_tt", replacement = "", x = .) %>%
paste0("https://www.imdb.com", ., "criticreviews?ref_=tt_ql_6")
# scrape metascore from each nested page url
metascores <- sapply(nested_page_urls, FUN = scrape_nested_pages) %>% as.numeric()
# coerce the number to a character so list entry is called by name (names are class char. not int.)
entry_number <- as.character(number)
# combine top-level and nested page scraping results into a data frame and store at the respective entry
store_data[[entry_number]] <- data.frame(title, year, director, runtime, gross_boxoffice, imdb_rating, metascores)
}
As before, we need to construct a data frame from the data we have acquired. You can, of course, also have a look at the result of your hard work:
# bind the list of stored data frames into a single data frame
imdb_data <- bind_rows(store_data)
# preview the data frame and view it's dimensions
glimpse(imdb_data)
# view the data frame
View(imdb_data)
Don’t flick the kettle on just yet though, the very last thing we should do is save the data. I will comprehensively cover reading and writing data in R in a future series. For now, let’s save the data frame as a .RData file called “imdb_scifi.RData”. I am going to do so in a directory called web_scraping located in my home directory:
# save output
save(imdb_data, file = file.path("~", "web_scraping", "imdb_scifi.RData"))
Congratulations on scraping yourself a data set to use in future tutorials!
The principles and tools covered in this series so far are good for a multitude of basic and intermediate level web scraping tasks with a little resourcefulness. However, web scraping workflows do go much deeper in terms of complexity and automation; I may cover intermediate and more advanced web scraping, and how to perform web scraping in an alternative language such as Python, in future.
I have one more post in this “Basic Web Scraping in R” series planned which will be a short one about scraping HTML tables. See you then.
Bonus Feature
In the last post I said I would include the script that I wrote while learning to use the rvest package to extract the same data set we have just scraped. I hope that this will demonstrate how the basic code we have written can be further developed into an efficient basic web scraping program with some minor alterations and more advanced constructs that I will be posting about in future. Click below to take a look:
Click to Show Code
## load packages
library("dplyr")
library("rvest")
## user defined functions
# single item text scrape
extract_html_text <- function(input, css_selector, nested = FALSE) {
if (!nested) {
input %>%
html_elements(css_selector) %>%
html_text()
} else {
read_html(input) %>%
html_elements(css_selector) %>%
html_text()
}
}
# top level page scraping
top_level_page_scrape <- function(...) {
# extract each component as a vector
name <- extract_html_text(..., ".lister-item-header a")
year <- extract_html_text(..., ".text-muted.unbold")
director <- extract_html_text(..., ".text-muted+ p")
runtime <- extract_html_text(..., ".runtime")
gross_boxoffice <- extract_html_text(..., ".sort-num_votes-visible")
imdb_rating <- extract_html_text(..., ".ratings-imdb-rating strong")
# combine all created vectors into a data frame returned by the function
data.frame(name, year, director, runtime, gross_boxoffice, imdb_rating)
}
# parse nested urls from top level page into vector of character strings
parse_nested_urls <- function(url) {
read_html(url) %>%
html_elements(".lister-item-header a") %>%
html_attr("href") %>%
sub(pattern = "\\?ref_=adv_li_tt", replacement = "", x = .) %>%
paste0("https://www.imdb.com", ., "criticreviews?ref_=tt_ql_6")
}
## setup for running for-loop
# sequence of top-level page numbers to use in the loop
top_level_numbers <- seq(from = 1, to = 801, by = 50)
# create storage object of length equal to output object - preallocation of memory
store_data <- vector(mode = "list", length = length(top_level_numbers))
# name the list entries allowing us to call these on each iteration and assign the data frame to that entry
names(store_data) <- top_level_numbers
## for-loop: sequentially iterates over top-level pages
for (number in top_level_numbers) {
# tell me which entries the loop is currently working on
cat("Working on entries beginning with entry", number, "\n")
# alter the top-level url by substituting the top =evel page number
url <- paste0("https://www.imdb.com/search/title/?title_type=feature&num_votes=25000,&genres=sci-fi&sort=user_rating,desc&start=",
number,
"&ref_=adv_prv")
# read the HTML code for the page at the specified URL
page <- read_html(url)
# scrape the data from the top-level page
top_level_data <- top_level_page_scrape(page)
# parse urls for nested pages into a vector of character strings
nested_page_urls <- parse_nested_urls(url)
# scrape the desired data from nested pages
metascores <- sapply(nested_page_urls, FUN = extract_html_text, css_selector = ".score_favorable span", nested = TRUE) %>% as.numeric()
# coerce the number to a character so correct list entry is called by name (names are class char. not int.)
entry_number <- as.character(number)
# combine top-level and nested page scraping results into a data frame and store at the respective entry
store_data[[entry_number]] <- data.frame(top_level_data, metascores)
}
## output result
# bind the list of data frames created by the for-loop into one
imdb_data <- bind_rows(store_data)
# save output
save(imdb_data, file = file.path("~", "web_scraping", "imdb_scifi.RData"))
Thanks for reading. I hope you enjoyed the article and that it helps you to get a job done more quickly or inspires you to further your data science journey. Please do let me know if there’s anything you want me to cover in future posts.
Happy Data Analysis!
Disclaimer: All views expressed on this site are exclusively my own and do not represent the opinions of any entity whatsoever with which I have been, am now or will be affiliated.